Edition 22: A framework to securely use LLMs in companies - Part 2: Managing risk
In this edition, we will focus on managing risk for applications leveraging 3rd party LLMs


In Part-1 of this series, we went over common risks that companies should watch out for as they adopt LLMs. This post (and the next one) will focus on managing these risks better.
The same caveat as the last post applies here. This is a fast-changing area and a lot of the ideas here come through secondary research, including interacting with companies who are trying to solve this problem. So, expect some ideas here to not age well and other ideas to not apply to your scenarios.
Hypothesis
For companies without an advanced data science program, integrating their applications with established 3rd party LLMs is the path of least resistance to LLM adoption. Company executives and engineering leaders understand the value LLMs bring but want to test the waters before spending a small fortune* on model training.
In this post, we will only focus on companies that are leveraging 3rd party LLM solutions in their applications. This means, risks like “training data poisoning” don’t apply (there are corner cases where it is applicable, but we will tackle that in future editions).
*While open source models can be used for free (or cost very little), the total cost of ownership (TCO) including diverting engineering resources, and uncertain infrastructure costs can be quite high. There is also the opportunity cost of having to de-prioritize other initiatives.
Using 3rd party LLM providers
The approach of leveraging 3rd party LLMs has the following advantages:
Minimal setup complexity in most cases. You can get up and running quickly.
It allows companies to experiment with minimal upfront investment (a few hundred dollars is all you’d need to get started with OpenAI). In some cases (we will see details later), there is no deployment costs either.
You don’t need a team to maintain LLMs systems. This is handled by the 3rd party (typical SaaS model)
Unsurprisingly, this approach comes with some open questions that need answering:
Is it safe to send our data to these 3rd parties?
Are the responses from these LLM tools trustworthy? How do we account for bias and hallucination? Is it safe to pipe these responses directly to our customers?
Given most LLMs charge you by the number of tokens consumed, what are the chances of cost overruns if the application starts sending a lot of traffic? At an even more basic level, how much budget should I allocate for LLMs per application?
Without answering these questions authoritatively, companies are hesitant to go all in on LLMs. They may use it to generate ad copy or make stunning images for marketing campaigns (which is a legitimate use case), but they will not integrate LLMs into their core workflows. As Security teams, we need to pave the way for broader, safer adoption.
Deployment options
Before we start answering the questions on risks, let’s take a step back and talk about the ways to deploy such a solution. Companies have 2 options:
Public SaaS - 3rd party model, 3rd party deployment: This is pretty much what the name suggests. You get an API key and secret. You send requests to an external service (e.g.: “prompts to OpenAI”) and you get your response. Each application may choose to use a different LLM and that’s fine too. This approach allows each application team to make their own choices, based on their preferences.

Each application chooses which 3rd party LLM to interact with Private SaaS - 3rd party model, deployed in-house: Things get interesting here. Companies like Google (GCP) and Microsoft (through Azure), understand that companies may be hesitant to send their data outside their networks. So, they allow you to deploy a copy of the entire LLM *inside* your cloud network. So, if you use the Azure OpenAI service, none of your prompts leave the building. Depending on what service you plan to use, there will be some gotchas to consider. In the case of Azure OpenAI, you will need to send the prompts back to Azure for abuse monitoring (you can opt out of “abuse monitoring”, but that’s not a good idea unless you have alternative solutions to monitor abuse). Unlike Public SaaS, it will be harder for each application to have its own Private SaaS instance given the upfront cost of getting it done is significant. In all probability, your company’s data science or IT team will purchase this solution and applications will be forced/requested to use this service.

Sample architecture for Private SaaS deployment. The “update service” is an abstraction for any calls the LLM layer needs to make to the mothership. side note 1 - Over time, I fully expect these offerings to come up with even more creative solutions for data sharing. We have seen this approach taken by other SaaS platforms and there is no reason to believe the same won’t happen to LLM. My guess is this deployment option will become the default for enterprises over time.
side note 2 - This model also allows companies to train the LLM layer with internal data. When done right, this can allow companies to have the best of both worlds. This will also open up the risks of “training data poisoning” while using 3rd party LLMs. We will steer clear of this use case for this post, but come back to it in later posts.


Overview of risks
Both deployment options have some risks. Depending on which deployment model you use, your risk profile changes a little bit. Here’s an overview of the risks for each option (for an overview of all risks, see Edition 21).

Managing risk
To summarize the table, depending on the deployment model, there are 4-5 key risks that any consumer of 3rd party LLMs should account for. To counter these risks, we propose 3 risk management techniques. In this post, we are focusing on “what” needs to be done. The “How” is a much harder question and out of the scope of this post. I bet that there will be at least a handful of startups that will answer the “How” question in the coming months and years. These are also measures that a solid Security Engineering team can build in-house.
An LLM gateway to route traffic: Going back to our lessons from AppSec, the most scalable way to reduce risk is to provide applications with a secure way to do this. To enable that, we recommend creating an abstraction layer through which all LLM traffic passes. This allows you to write rules to mask sensitive data, keep a tab on costs and monitor for abuse. Furthermore, it also allows you to route the traffic to different LLM providers (if that’s a requirement). The LLM response will also route through the same layer to check for bias, hallucinations, and leakage of sensitive information before passing the response back to the application. Like a typical gateway, this layer can choose to run in “pass-through” mode (just monitor and report) or “blocking” mode, where decisions can be taken to drop requests or responses.
Below are sample architecture diagrams for “public SaaS” and “Private SaaS” options.
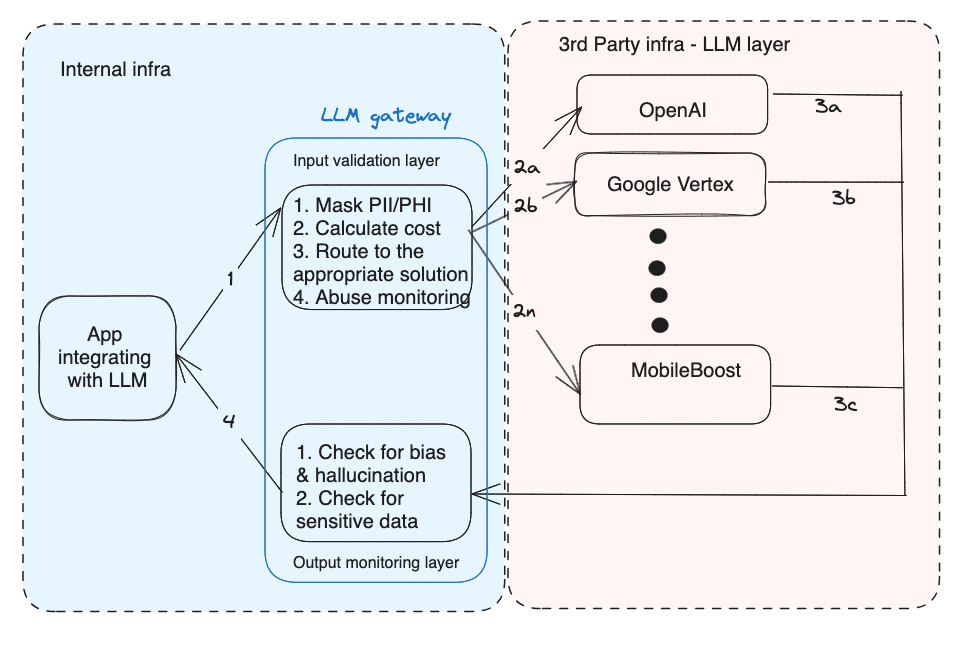
In addition to managing risks, in a Public SaaS model, the LLM gateway can also provide a routing mechanism to make things simpler for applications. 
The same gateway can be tuned to manage a slightly different set of risks in the Private SaaS model Regular auditing/testing of implemented solutions: Even with the LLM gateway in place, there is a need for good old pen testing / red teaming activities. Controls fail, shadow IT is real, and an adversarial mindset will always uncover more risk. Having said that, we may not need a new “LLM audit” team. This function can be folded into your current Security team. Ensuring the team comes up with LLM-specific test cases during pen tests, red teams, security code reviews, and threat modeling exercises is key.
Additional points if the audit teams can provide feedback to improve the LLM gateway :)
A monitoring layer to monitor LLM usage: While the gateway layer helps application teams to build the integration securely, it's reasonable to assume that most medium-large organizations will have “shadow” usage. The goal of the monitoring layer is to build an inventory of (all) usage and call out any concerns. Given this goal, some of the capabilities may overlap with the gateway layer and that’s OK.
DNS monitoring can be leveraged to detect if applications are making calls to unapproved LLM services. For example: In the AWS environment, VPC Flow Logs, and Route53 Resolver Logs can be used to identify the invocation of services like OpenAI.
Using a similar technique, we can monitor the volume of data sent to services such as OpenAI.
Cost monitoring: A tool to monitor how much money is being sent on requests made to LLM tools. This is easier said than done as not all LLM tools provide you with an easy way to get this data from their systems. This is even trickier when there is significant shadow usage.
Sensitive data monitoring (PII, PHI): Analyze logs from the LLM gateway and the applications to see if there are hints of sensitive data being accidentally sent to 3rd party LLMs. This risk becomes more important to manage in the Public SaaS model.
Static monitoring:
Write static analysis (Semgrep, CodeQL) rules to detect if any applications are integrating with LLM libraries.
Leverage SCA tools to check if insecure LLM libraries are used in applications integrating with LLMs
Container image scanning: Generate an SBOM and detect if insecure, 3rd party LLM library is used


What next?
Each of the above risk management techniques is non-trivial to implement. You either need a rock-star team of security engineers or a vendor with these offerings to operationalize this (ideally, both). Like all risk management initiatives, prioritization is key. Depending on your risk appetite, the risk profile of the applications being integrated with LLMs, and your budget, a prioritization framework should be applied to build these out. Read more on why prioritization is critical for Security teams in edition 19.
Credits
Many people have contributed in meaningful ways to make this edition of BoringAppSec happen. Special thanks to Ashwath Kumar, Pete Zimmerman, and Vinay Vishwanatha for their insights.
That’s it for today! Are there other risk management initiatives that are missing from the post? Are there interesting companies or open-source projects working on building these out? Tell me more! You can drop me a message on Twitter, LinkedIn, or email. If you find this newsletter useful, share it with a friend, or colleague, or on your social media feed.