Edition 6: Top 4 AppSec metrics and why they are so hard to measure
You can't improve what you cannot measure, but measuring incorrectly can drive incentives in the wrong direction. Here's a hypothesis on "good" AppSec metrics and why they are so hard to measure.


Ever since I read "How to measure anything" by Douglas Hubbard (highly recommended) for work a few years ago, I have been thinking a lot about what are the "best" metrics we can use to measure AppSec. There are many excellent references on measuring Cybersecurity risk. In this edition we will focus (as always) on measuring AppSec.
Like all metrics, the objective of measurement is to reduce uncertainty by analysing available data. Uncertainties such as:
Is our AppSec program getting better over time?
Are our investments in tools/people/processes yielding results (i.e. reduced risk posture)?
The problem is, there are no measurements that can precisely answer these questions. However, we can use a few proxies which offer clues and hence, reduce uncertainties.

So here's my hypothesis:
By measuring code coverage, defect density, Mean time to detection (MTTD) and mean time to remediation (MTTR), you can answer key questions which help reduce uncertainties about the efficacy about your AppSec program. By measuring these over time, you can also evaluate if your program is trending in the right direction.
Code coverage

While many companies do a good job at protecting the crown jewels, it’s often that one open S3 bucket or that public facing Oracle DB with scott/tiger that leads to a breach. With cloud computing and super fast release cycles, we have made it extremely easy to create and deploy applications without friction. While this is good in general, it also means certain necessary friction (like security assessments) may never happen.
Given this, it is important to know what percentage of the software we use (custom + COTS + SaaS) actually comes under our assessment lifecycle. While 100% is a hard goal to acheive, consistently improving coverage should be a reasonable target.
Why is this hard to measure?
If we use the above formula to measure code coverage, getting the value of the denominator requires us to have a robust inventory. Building a complete, up to date inventory is a challenge for any organization of reasonable size. So, unless we crack the inventory problem, we cannot really crack the code coverage problem (more on software asset inventories in editions 1 and 2 of this newsletter).
This is also a metric that can be easily gamed by having shallow, mostly automated “scans” across the portfolio. While the scores may improve by doing that, we would be misssing the woods for the trees. Building high quality AppSec assessments is important too. More on assessment types and how to evaluate them in edition 3 .
Defect density
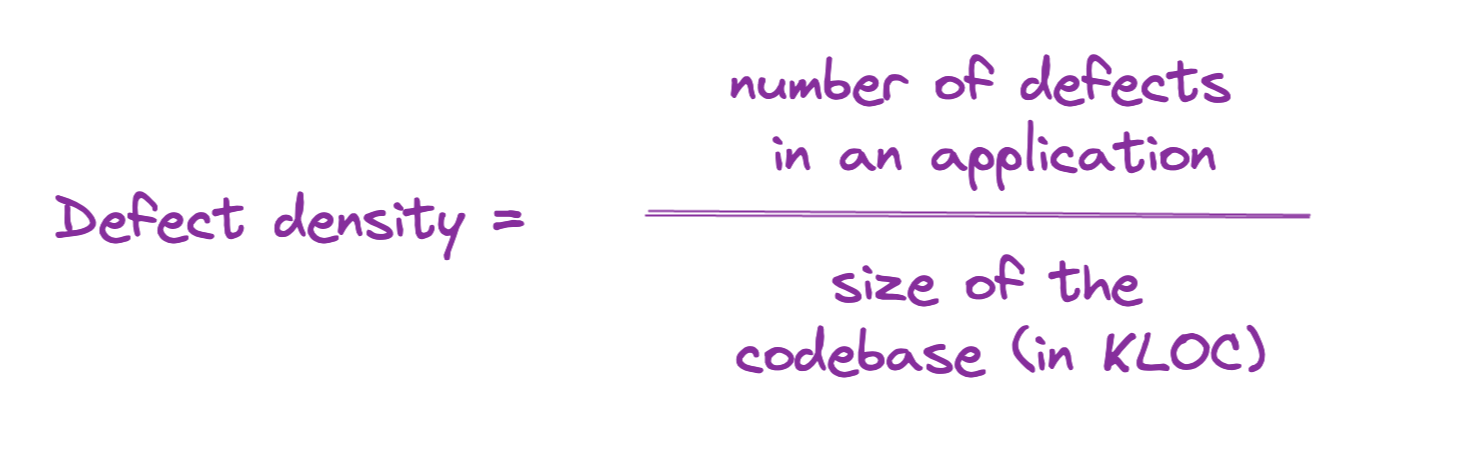
OK, so now we know what percentage of your portfolio goes through assessments. Its’s important to know how many defects we find in our applications. For software where you own (or have access to) the source code, the above formula is helpful. For software you don’t own (COTS or SaaS products), we may have to use a different denominator (number of pages or size of the binary are possible, but imperfect options).
Why is this hard to measure?
There are a couple of reasons:
We cannot always map a defect to a line of code. While vast majority of AppSec defects are due to errors in code or flaws in design, some of them are not related to code at all. For exmaple: Overly broad permissions to a type of user or an error in your infrastructure configuration. In such cases, it becomes hard to define the denominator.
note: Infrastructure as code (IaC) initiatives can make it simpler to calculate defect density for infrastructure related defects too.As mentioned earlier, finding a denominator that works for SaaS and COTS applications is hard. Even once we make that choice, it is hard to make comparisons between COTS and custom built software.
Mean time to detection (MTTD)

This one is straight forward. Caclulate the average amount of time taken to detect a defect. If your organization has a lot of security debt, this number could be in months. Having reasonable targets to reduce it each quarter, instead of a grand goal such as “MTTD should be a few seconds”, is helpful. This metric helps us understand if the efficacy of AppSec assessments are trending in the right direction.
Also, note that we are calculating the date from when the code was pushed to production. So, if we discover the defect before its pushed to production (say through a SAST tool that runs in your pipeline), TTD should be considered zero (0). This can act as an excellent incentiy for developers to adopt assessment tools earlier in the lifecycle :)
Why is this hard to measure?
There are a few challenges with measuring MTTD. If you use old school source code management tools (e.g.: CVS, SVN or — horror — just flat files), it is harder to figure out when code was checked-in. This makes it impossible to calculate MTTD.
For SaaS/COTS, we will have to find a different equation since we do not “check in” the code ourselves. The date the application was deployed in our environment is a good alternative, but YMMV.
Finally, for open source packages used, TTD gets even trickier. The date the code was checked in is usually present, but should we consider that or the date we included it in our codebase? Decisions decisions…
Mean time to remediate (MTTR)

This one is straightforward to understand and measure. It is also possibly the most important metric. Security posture does not improve when we find defects. It improves when the fix them. Fixing defects early reduces your chances of falling victim to an attack. Unlike the other 3 metrics, reducing MTTR also judges the efficacy of the application teams. No amount of evangelization or tooling from the security team can reduce MTTR, if app teams don’t actually fix defects.
What next?
A few things to keep in mind if you plan to use these metrics in your measurements:
Avoid idealistic targets: Have reasonable targets for each metric. Getting to 100% code coverage or MTTD on 24 hours sounds great on paper, but will make the target too hard to achieve. You are better of measuring where you are and setting “reasonable targets”.
Track at various levels: The “reasonable target” does not have to the same across your org. Have different targets for different parts of your organization. A business unit which builds your crown jewels should have a more aggressive target than the one which build developer productivity tools. As with everything in Security, it’s important to have a risk-based approach to metrics too.
Add context to data: Appreciate that events not in your control can throw off the average. For instance, if your company just acquired a small pre-revenue startup, chances are they have a ton of defects, which will drive up defect density. Chances are, their code is written in a language your SAST tool does not support, so your code coverage drops too. Adding context when you present data is key.
Don’t obsess over precision: Earlier in this post, we discussed challenges with measurements (e.g.: Denominator to measure defect density in COTS). While it’s important to try and solve the hard problems, sometimes, perfect can be the enemy of good. It’s better to use the same imperfect measurement consistently across the portfolio than not measure while waiting to create the perfect measurement.
That’s it for today! As mentioned earlier, this is my hypothesis for what “good” AppSec metrics are. I am hoping to try some of these in the coming years. Maybe a future edition will talk about how it went :) . If you have used similar metrics to measure AppSec or have other metrics that should be added to this list, hit me up! You can comment here or drop me a line on twitter, LinkedIn or email. If you find this newsletter useful, do share it with a friend, colleague or on your social media feed.